Advertisements
楊凈 子豪 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
首先,請先看一段“ 正經”的文字:
橋豆麻袋!!!
這難道不是 什么某某天堂、某江文學、某點中文上的小說情節?

誤會了誤會了。
這是最新發布的全球最大規模中文預訓練模型“中文版GPT-3”—— PLUG的力作。
270億的參數規模,跟GPT-3一樣是“萬能寫作神器”。
出于好奇,我第一時間就去上手試了試,沒想到只是輸入了四個字。
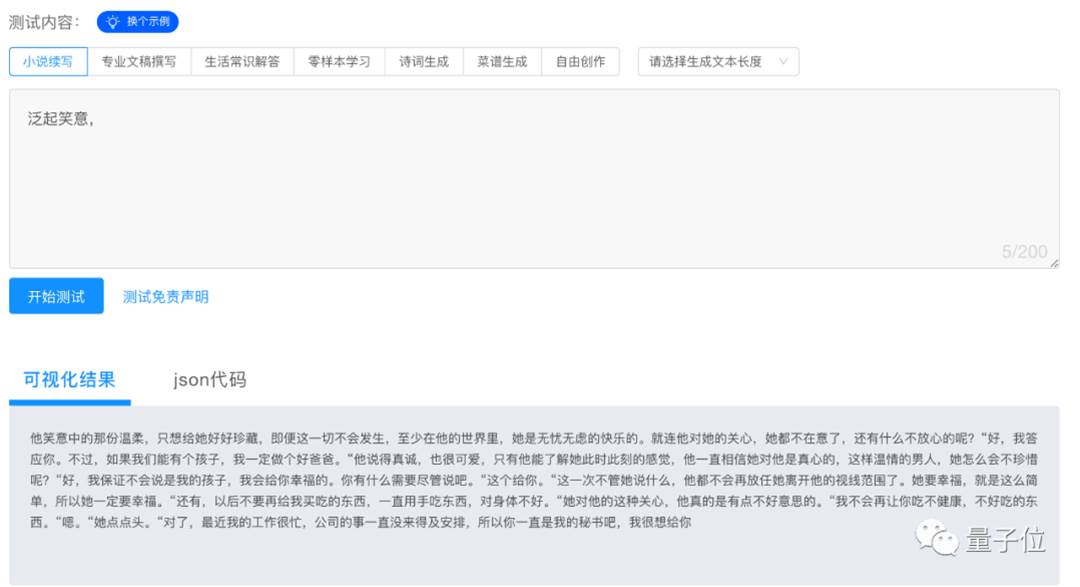
就給出了如此結果。
這個PLUG,有點意思啊~

竟然擅長的是這個?
接下來,我又進行了一波嘗試,調戲一下PLUG的創作實力。
輸入「他正要離開」,看它怎么接。
PLUG果然很懂!
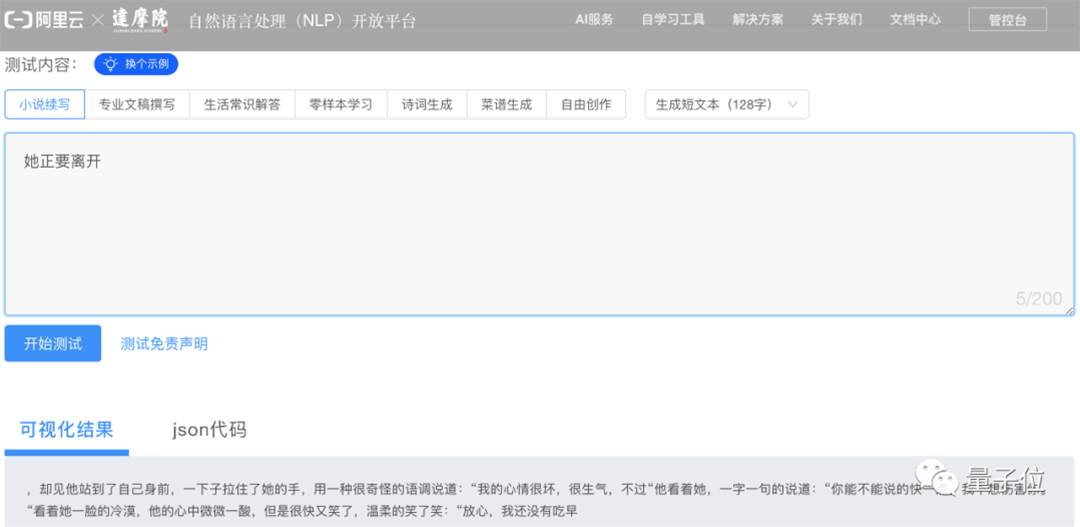
有一說一,生成 長文本的性能還是相當不錯,并且提供了4個 文本長度選項(32~512字)。
不過這內容……
難不成,我喜歡XX文的秘密被發現了?

別誤會,其實PLUG也能生成“克制”一些的。
比如:輸入「阿sir,你看看他」,結果就顯得很正常嘛~
甚至還特意生成了繁體字小說,營造出一種港片的氛圍感。
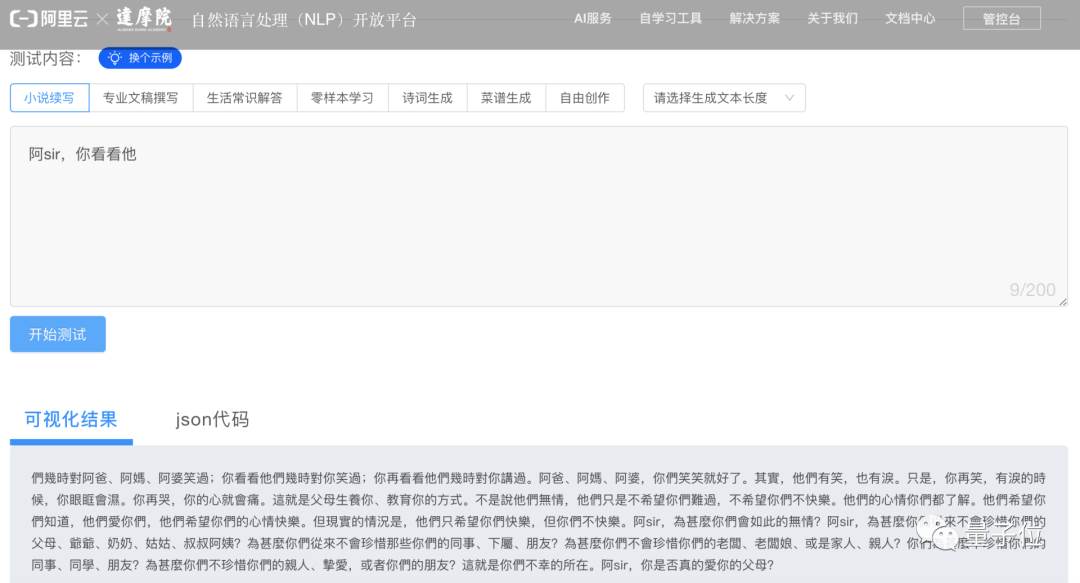
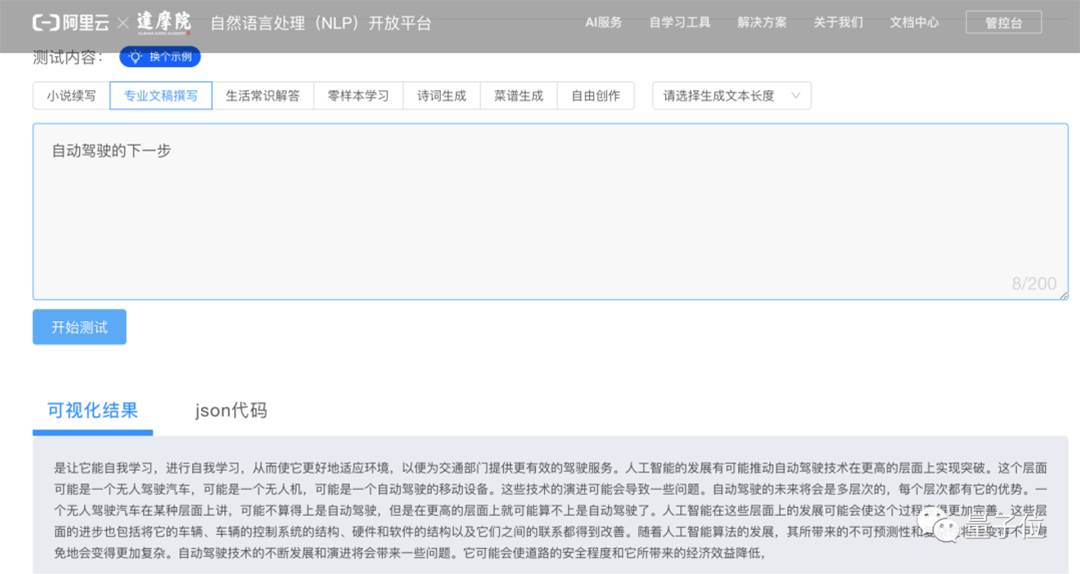
除了擅長寫小說,PLUG還能寫專業文稿、進行智能問答、生成詩詞和菜譜等等。
就比如 撰寫專業文稿:
幫你 解答生活常識,官網給出了貼心 (不是)的示例:
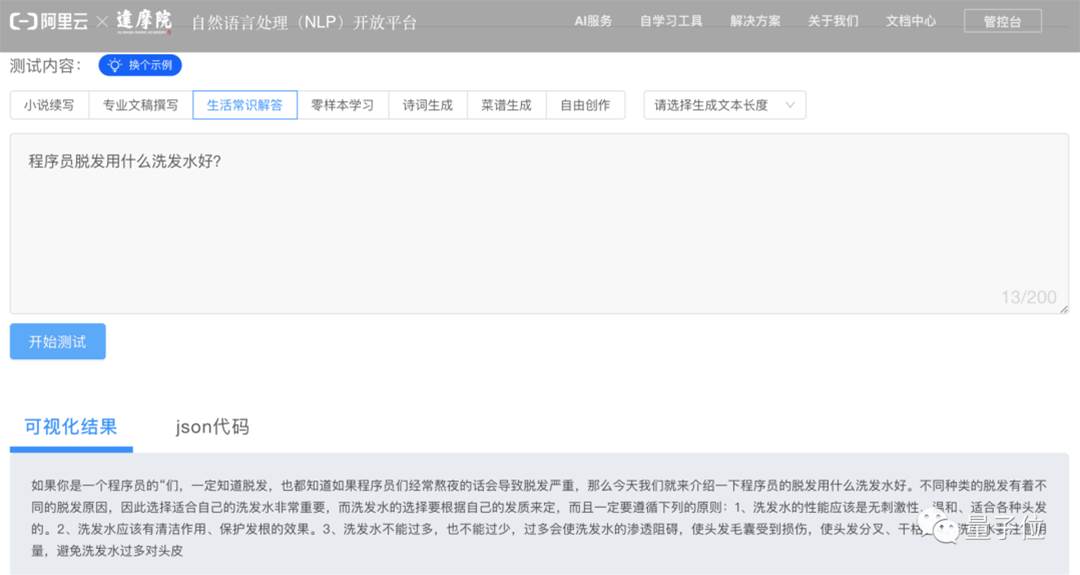
三個月打造中文最強GPT-3
說了這么多,要達到這樣的效果,這個中文最強GPT-3究竟如何煉成?
PLUG,Pre-training for Language Understanding and Generation,顧名思義,就是集語言理解 (NLU)和生成 (NLG)能力于一身。
要實現這一點,據團隊介紹,這一模型是達摩院此前提出的兩種自研模型——NLU語言模型 StructBERT、NLG語言模型 PALM的融合。
此外,跟GPT-3的單向建模方式不同的是,它采用了編碼器-解碼器 (encoder-decoder)的 雙向建模方式。
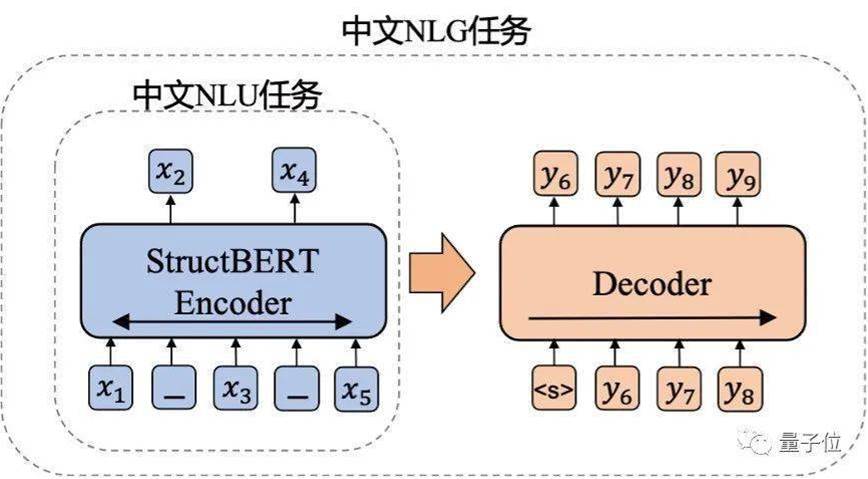
具體來說,整個訓練過程分為兩個階段。
第一階段,以達摩院自研的語言理解模型—— StructBERT作為編碼器。
簡單來說,它是在 句子級別和 詞級別兩個層次的訓練目標中,加強對語言結構信息的建模,從而提高模型的語法學習能力。
這也使得PLUG具有輸入文本 雙向理解能力,能夠生成和輸入 更相關的內容。
這個過程共訓練了300B tokens訓練數據。
第二階段,將這個編碼器用于生成模型的初始化,并外掛一個6層、8192個隱藏層節點數的解碼器,共計訓練了100B tokens的訓練數據。
此外,PLUG還能為目標任務做針對性優化。
上一回說到 ,GPT-3并沒有利用 微調和 梯度更新,而是通過指定任務、展示少量演示,來與模型文本進行交互,完成各種任務。
因此在面對新任務時候,不需要重新收集大量的帶標簽數據。但不可避免的,生成的效果不足。
比如, 犯低級錯誤就是GPT-3被人詬病比較多的一點。
而PLUG的能力更加 全面,既可以實現與GPT-3類似的零樣本生成功能,也可以利用下游訓練數據 微調 (finetune)模型,提升特定任務的生成質量。
當然,效果實現的關鍵,還少不了 算力和數據。

PLUG負責人表示,原本計劃用 128張A100訓練120天煉成,不過由于阿里云、算法優化等達摩院多方力量的參與,以及加速手段的有效利用,成功將日程縮短到三分之一。
最后,只燒了35天就達到了這樣的效果。
前面也提到,PLUG的參數量達到了 270億,中文訓練數據量也達到了1T以上。
在語言理解任務上,PLUG以80.614分刷新了CLUE分類任務榜單記錄。
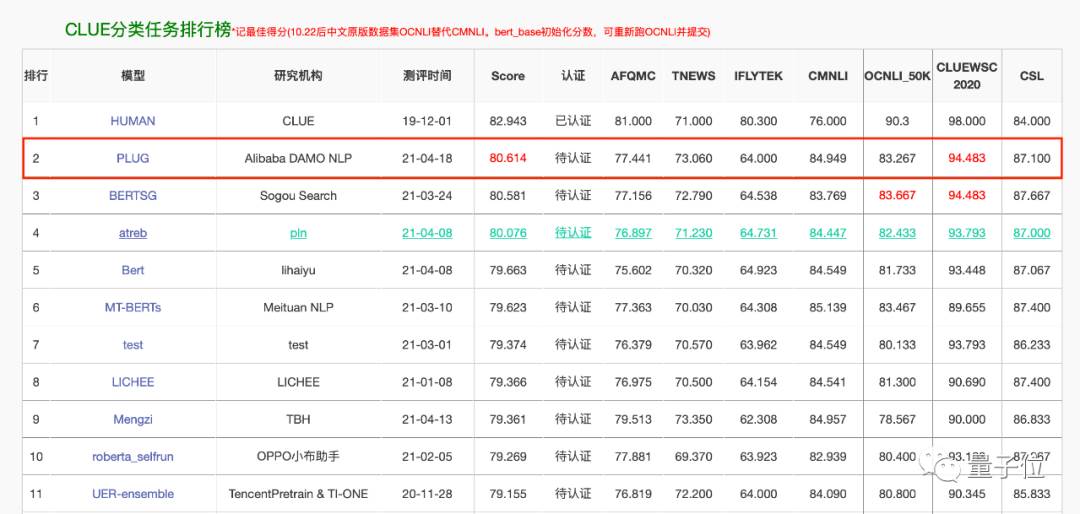
而在語言生成任務上,據團隊介紹,其多項應用數據較業內最優水平提升了 8%以上。
語言模型體系再添一員大將
如果再把PLUG說成是“中文版GPT-3”,似乎就不太準確了。
耗時3個月、270億參數規模、一發布就給體驗端口……
但與此同時,這些關鍵詞的背后,仍然留給讀者一些疑問:
阿里深度語言模型體系負責人 永春給出了一一解答。
首先,時間問題。主要有兩個方面的原因。
從人力的角度來說,永春沒有談具體的數字,但此次涉及阿里的多個團隊群策群力共同完成的,當中的訓練時間也就大大縮短。
再加上,阿里以往的自研模型已經產生了更多的業務需求,促成了PLUG的開發,這也是阿里整體技術路線中的一環。
GPT-3的出現,給中國的一些玩家觸動很大。
阿里作為其中之一的企業,利用自身的技術、計算資源的優勢,率先給出 Demo。
永春表示,希望通過PLUG的發布,建立起與技術同行之間的橋梁。
要知道,GPT-3到目前也還沒有做到完全開放。
不過,團隊似乎并不擔心PLUG發布之后的一些不確定性。 (手動狗頭)
比如,出現一些低級錯誤。
反而笑著說,之前GPT-3不也是因為大家吐槽才火的么?丟給技術圈去檢驗,這些問題都是不可避免的。

而這樣的 開源開放,正好是這個技術團隊的一大底色。
去年,阿里達摩院發布了自研 深度語言模型體系,包括6大自研模型。
通用語言模型StructBERT、多模態語言模型StructVBERT、多語言模型VECO、生成式語言模型PALM……他們一直在致力于陸陸續續將模型開源出來。
永春透露,在PLUG發布這段期間,達摩院宣布將開源阿里巴巴語言模型體系部分重要模型,目前正在走流程中。
至于之后的計劃,團隊表示 2000億級的參數規模正在規劃中,并進一步提升文本生成質量。
而在應用領域,他們還將專門針對醫療領域做下游數據訓練。
最終目標是希望將這個模型實際落地,提升NLP技術在方方面面的實力,比如能源、通信、司法等。
也誠如阿里達摩院語言技術實驗室負責人司羅所說,
對了, PLUG剛剛完成最后一波調控,目前已開放了測試體驗接口(僅供學術目的測試,需同意其相關約定)。

— 完—
本文系網易新聞•網易號特色內容激勵計劃簽約賬號【量子位】原創內容,未經賬號授權,禁止隨意轉載。
點這里大家都在玩的社團☞熱門大爆料☜加入社團和大家一起交流